1. Introduction
La norme 802.1x définit le réseau à accès contrôlé. Ceci est très utilisé dans le lieu public tel que les Hotspots des Aéroports, les restaurants, les gares, les hotels, etc…
L’infrastructure 802.1x permet à la fois sécuriser et aussi contrôler les accès aux services proposés. On peut alors tracer des accès, identifier l’utilisateur du service et enfin définir les services proposés par avance.
Cette infrastructure, fonctionne aussi bien avec le réseau sans fil que filaire.
2. Caractéristique du 802.1x
Pour créer une infrastructure 802.1x, nous avons besoins de mettre en place les composants ci-dessous pour former une architecture d’un réseau à accès contrôlé.
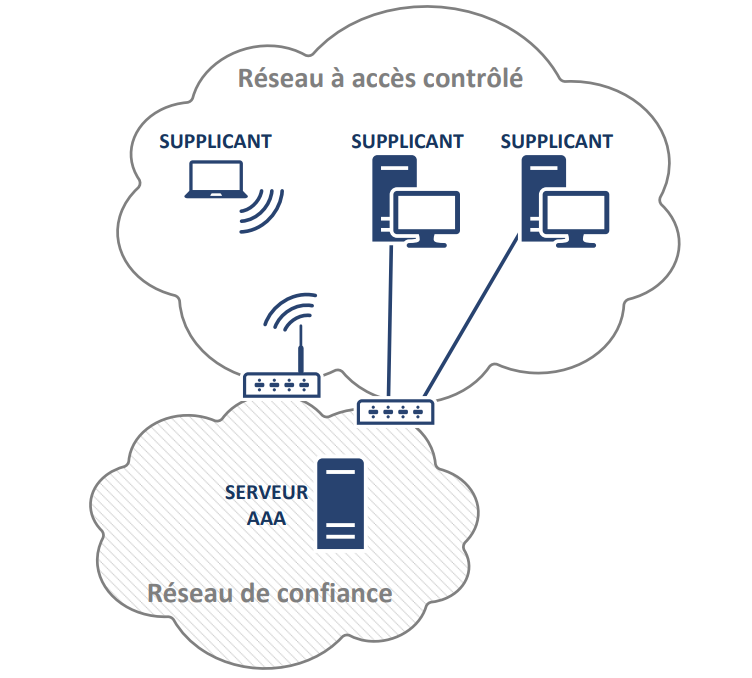
2.1 Les composants 802.1x
Serveur AAA : Authentication, Authorization, Accounting (Authentification, Autorisation et Traçabilité). Serveur AAA est un serveur qui offre les services d’authentification, d’autorisation et de traçabilité des évènements.
Le Client : élément de confiance d’un réseau 802.1X servant de point d’accès au réseau (commutateur, point d’accès Wi-Fi…). Cet élément est appelé authenticator dans la norme 802.1X.
Supplicant : logiciel sur l’équipement d’extrémité cherchant à se connecter à un réseau à accès contrôlé, afin de fournir une connectivité Ethernet à l’équipement d’extrémité.
EAP : Extended Authentication Protocol, protocole réseau permettant d’abstraire le mécanisme d’authentification spécifique utilisable.
EAPoL : Extended Authentication Protocol over LAN, protocole d’encapsulation de trames EAP sur des réseaux locaux. C’est un protocole qui repose sur Ethernet et qui dispose de son propre Ethertype 2 0x888E.
Réseau à accès contrôlé : réseau dont l’accès doit être protégé par des mécanismes AAA.
Réseau de confiance : réseau maîtrisé dans lequel le serveur et les clients communiquent.
2.2 Fonctionnement
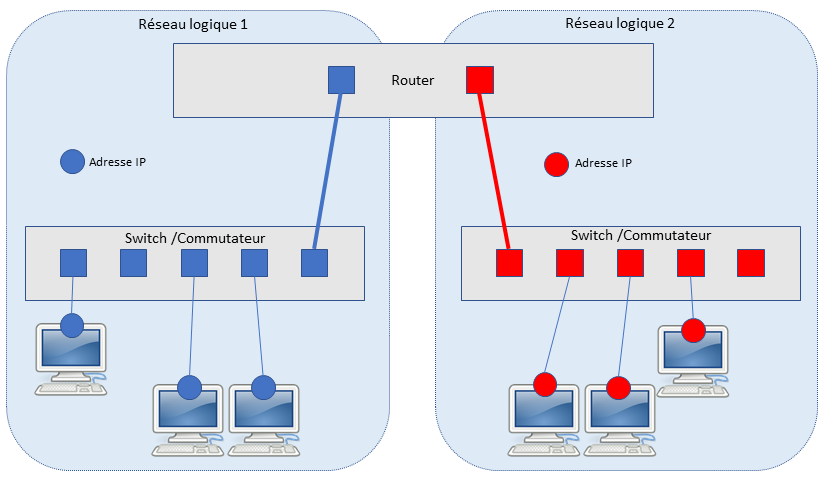
Le schéma ci-dessus montre que nous avons deux zones du réseau à accès contrôlé et du réseau de confiance. Les deux réseaux s’interconnectent via un système de routage L3 utilisant deux LAN différents séparés physiquement ou différent VLAN.
Dans sa granularité, lorsqu’un utilisateur a besoin d’un accès aux services qui présentent sur le réseau de confiance, il connecte le supplicant au réseau à accès contrôlé, ceci se dirige le flux vers le serveur AAA en ouvrant le canal de communication auquel passe via le routeur qui sépare les deux réseaux. Via le processus d’authentification, si le supplicant est identifié, l’accès sera autorisé, sinon l’accès sera refusé. Voilà, c’est tout simple !
2.3 Le réseau de confiance
Par définition, c’est un réseau considéré comme sûr, Il transporte les informations d’authentification et d’autorisation des équipements finaux et les différentes données de journalisation remontées par les clients au serveur. Les clients d’un réseau 802.1X sont des équipements tels que des commutateurs (switchs) ou des points d’accès Wi-Fi qui fournissent une connectivité au réseau à accès contrôlé à l’aide de ports de connexion. Ils sont connectés au réseau de confiance, pour accéder aux services. Les ports de connexion peuvent se trouver dans deux états :
Dans l’état autorisé, un port accepte tout trafic en provenance et à destination du supplicant connecté, notamment le trafic IP ;
Dans l’état non autorisé, seul le trafic EAPoL est autorisé entre le client et le supplicant.
Par défaut, ils sont dans l’état non autorisé et leur changement d’état est commandé par le serveur après authentification et autorisation d’un supplicant. Durant cette phase d’authentification, les clients réalisent une rupture protocolaire entre le supplicant et le serveur. En effet, la communication avec les supplicants s’effectue au moyen du protocole EAPoL alors qu’elle s’effectue à l’aide du protocole du réseau de confiance entre les clients et le serveur (RADIUS sur IP dans la plupart des cas). La connectivité Ethernet des supplicants est donc inexistante avant leur autorisation d’accès au réseau à accès contrôlé.
2.4 Le réseau à accès contrôlé
Le réseau à accès contrôlé est le réseau dont les accès doivent être maîtrisés. Il est connecté aux différents clients et aux supplicants. Le terme réseau à accès contrôlé désigne par extension l’ensemble des réseaux utilisateurs (physiques ou virtuels) dont l’accès doit être contrôlé centralement.
2.5 Supplicants
Les supplicants cherchent à se connecter au réseau à accès contrôlé au travers des ports de connexion offerts par les clients. L’accès à ce réseau est autorisé ou refusé après une phase d’authentification et d’autorisation dans laquelle les trois équipements (supplicant, clients et serveur AAA) interagissent. Une fois leur accès au réseau autorisé, les supplicants sont connectés au réseau à accès contrôlé.
3. Synoptique de connexion
La connexion à un réseau à accès contrôlé s’effectue en quatre étapes.
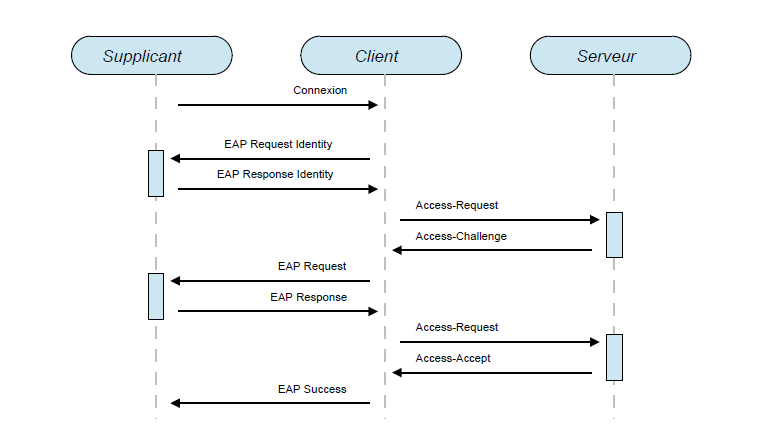
- Initialisation : le client détecte la tentative de connexion du supplicant à un port dont l’accès est contrôlé, il active le port en mode non autorisé.
- Identification :
- Le client transmet au supplicant une demande d’identification (trame EAP-Request/Identity) ;
- Le supplicant retourne au client son identité (trame EAP-Response/Identity) ;
- Le client transmet l’identité du supplicant au serveur (paquet Access-Request).
- Négociation EAP :
- Le serveur envoie au client un paquet contenant la méthode d’authentification demandée au supplicant (paquet Access-Challenge) ;
- Le client transmet la demande du serveur au supplicant au travers d’une trame EAP-Request ;
- Si le supplicant accepte cette méthode, il procède à l’étape d’authentification au moyen de celle-ci, sinon il renvoie au client les méthodes qu’il supporte et l’étape de négociation recommence.
- Authentification :
- Le serveur et le supplicant échangent des messages EAP-Request et EAP-Response par l’intermédiaire du client suivant la méthode d’authentification choisie,
- Le serveur fournit une réponse Access-Accept ou Access-Reject suivant le résultat de l’authentification et de l’autorisation du supplicant :
- Si la réponse est Access-Accept, le client bascule le port de connexion dans l’état autorisé, le supplicant dispose ainsi d’une connectivité Ethernet au réseau à accès contrôlé,
- Si la réponse est Access-Reject, le port reste dans l’état non autorisé et le supplicant ne dispose d’aucun accès réseau hormis au travers du protocole EAP. À la fin de la connexion (déconnexion logicielle entraînant un message EAP dédié ou changement de statut du lien physique), le client modifie l’état du port à non autorisé.
4. Protocole de communication
Pour contacter le serveur AAA, les supplicants utilisent le protocole EAP. Ce protocole d’authentification extensible définit plusieurs méthodes d’authentification possédant différents niveaux de sécurité.
4.1 EAP-MD5
Le supplicant authentifie par défi-réponse EAP et sur la fonction de hachage MD5. Cette méthode offre un faible niveau de sécurité, car cette méthode est vulnérable à des attaques par dictionnaires et de l’homme du milieu. De plus, elle ne permet pas d’authentifier le serveur et ne peut pas être utilisée dans des réseaux sans fil par l’absence de négociation des clés cryptographiques durant l’authentification.
4.2 EAP-MSCHAPv2
Authentification mutuelle des correspondants qui repose sur un mot de passe et des défis cryptographiques. Cette méthode offre un niveau de sécurité faible, elle est vulnérable à des attaques par dictionnaires et sa résistance est équivalente à celle d’une clé DES.
4.3 EAP-TLS
EAP-TLS est un protocole d’authentification mutuelle du supplicant et du serveur par certificats. Cette authentification est réalisée à l’aide de TLS. Cette méthode nécessite que le serveur et chaque supplicant possèdent un certificat. Elle impose donc l’utilisation d’une infrastructure de gestion de clés (PKI) dans le système d’information. Ce protocole d’authentification est considéré comme sûr. Il expose cependant l’identité du supplicant durant la connexion, au travers du Common Name du certificat ou du champ Identity de la réponse EAP. Suivant le scénario de déploiement envisagé, cette information peut être considérée comme sensible. L’implémentation de cette fonctionnalité est cependant optionnelle et elle reste peu implémentée dans les serveurs et les supplicants existants.
4.4 EAP-PEAP
Ce protocole d’authentification est souvent dénommé PEAP dans la littérature. Initialement créé et défini par Microsoft, ses spécifications sont disponibles en accès libre sur le site de l’éditeur. Le protocole PEAP propose plusieurs versions et évolution.
Le protocole PEAP fonctionne en deux phases. Durant la première phase, le serveur s’authentifie auprès du supplicant au moyen d’un certificat pour créer un tunnel TLS entre les deux parties. Il procède ensuite à l’authentification du supplicant dans le tunnel TLS au moyen d’une méthode EAP appelée méthode interne. Les échanges réalisés par cette méthode interne sont protégés par le tunnel TLS établi. Cette construction permet l’utilisation de protocoles reposant sur les mots de passe pour l’authentification des supplicants. La méthode d’authentification interne la plus couramment utilisée est la méthode EAP-MSCHAPv2 et dans ce cas, le protocole est appelé PEAP-MSCHAPv2. PEAP peut également utiliser d’autres méthodes internes comme EAP-TLS pour authentifier les supplicants. Le protocole PEAP requiert uniquement un certificat serveur, l’utilisation de certificats clients est optionnelle et dépend de la méthode interne choisie. La mise en œuvre de ce protocole permet d’atteindre un niveau de sécurité correct, sous réserve d’appliquer les recommandations détaillées de ce document.
4.5 EAP-TTLSv0
Le protocole EAP-TTLSv0, aussi appelé EAP-TTLS, est un protocole d’authentification en deux phases, dont le fonctionnement est similaire au protocole PEAP. Ces protocoles restent cependant différents et incompatibles. Durant la première phase, le supplicant authentifie le serveur au moyen d’un certificat afin de créer un tunnel TLS entre les deux parties. L’authentification du supplicant s’effectue durant la seconde phase, à l’intérieur du tunnel TLS précédemment créé et à l’aide d’une méthode d’authentification interne (inner method). Cette méthode peut être une méthode EAP (EAP-MD5 par exemple) ou non EAP comme MSCHAPv2. Dans la majorité des déploiements, les méthodes internes utilisées sont PAP, EAP-MD5, EAP-MSCHAPv2 ou MSCHAPv2. Le protocole EAP-TTLSv0 présente plusieurs avantages :
L’identité du supplicant est masquée durant la phase d’authentification ;
Plusieurs méthodes internes peuvent être utilisées, sachant qu’elles sont souvent déjà mises en place dans un système d’information ;
Il requiert uniquement un certificat serveur, l’utilisation de certificats clients n’est pas obligatoire. L’utilisation de ce protocole permet d’atteindre un niveau de sécurité correct sous certaines conditions de déploiement.
5. Limite du 802.1x
La mise en place d’un réseau 802.1X apporte plusieurs fonctions de sécurité, dont une traçabilité précise des accès réseau effectués. Les messages de journalisation permettent par exemple d’identifier précisément les modifications de branchements d’équipements et les violations de politiques de sécurité. Cependant elle ne permet pas de protéger le système d’information contre toutes les menaces envisageables.