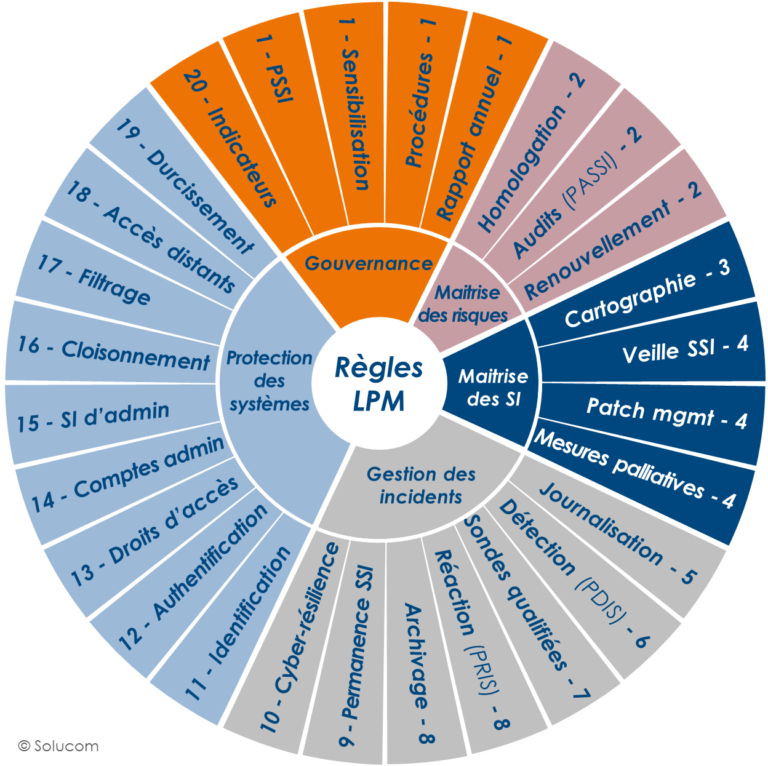
Règle 1 – Règle relative à la politique de sécurité des systèmes d’information
1.1-L’opérateur d’importance vitale élabore, tient à jour et met en œuvre une politique de sécurité des systèmes d’information (PSSI).
1.2-La PSSI décrit l’ensemble des moyens organisationnels et techniques, en particulier …
1.3-La PSSI et ses documents d’application sont approuvés formellement par la direction de l’opérateur.
1.4-L’opérateur élabore au profit de sa direction, au moins annuellement, un rapport sur la mise en œuvre de la PSSI et de ses documents d’application
1.5-La PSSI, ses documents d’application et les rapports sur leur mise en œuvre sont tenus à la disposition de l’ANSSI
Règle 2 – Règle relative à l’homologation de sécurité
2.1-L’opérateur d’importance vitale procède à l’homologation de sécurité de chaque système d’information d’importance vitale (SIIV)
2.2-Mise à disposition de l’ANSSI du dossier d’homologation. L’opérateur tient à la disposition de l’ANSSI les décisions et dossiers d’homologation, notamment les rapports d’audit
Règle 3 – Règle relative à la cartographie
3.1-L’OIV élabore et tient à jour les éléments de cartographie suivants …
3.1.1-L’OIV élabore et tient à jour l’élément de cartographie suivant : les noms et les fonctions des applications, supportant les activités de l’opérateur, installées sur le SIIV
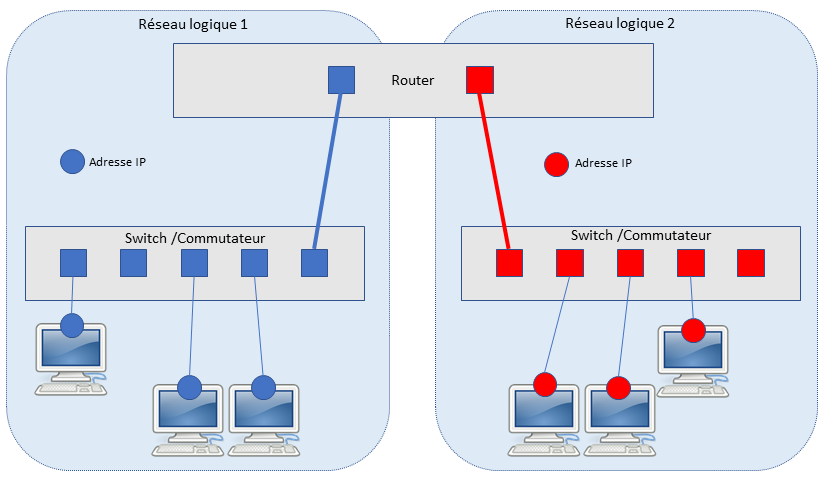
3.1.2-Le cas échéant, l’OIV élabore et tient à jour l’élément de cartographie suivant : les plages d’adresses IP de sortie du SIE vers internet ou un réseau tiers, ou accessibles depuis ces réseaux
3.1.3-Le cas échéant, l’OIV élabore et tient à jour l’élément de cartographie suivant : les plages d’adresses IP associées aux différents sous-réseaux composant le SIIV
3.1.4-L’OIV élabore et tient à jour l’élément de cartographie suivant : la description fonctionnelle et les lieux d’installation du SIIV et de ses différents sous-réseaux
3.1.5-L’OIV élabore et tient à jour l’élément de cartographie suivant : la description fonctionnelle des points d’interconnexion du SIIV et de ses différents sous-réseaux avec des réseaux tiers, notamment la description des équipements et des fonctions de filtrage et de protection mis en œuvre au niveau de ces interconnexions
3.1.6-L’OIV élabore et tient à jour l’élément de cartographie suivant : l’inventaire et l’architecture des dispositifs d’administration du SIIV permettant de réaliser notamment les opérations d’installation à distance, de mise à jour, de supervision, de gestion des configurations, d’authentification ainsi que de gestion des comptes et des droits d’accès
3.1.7-L’OIV élabore et tient à jour l’élément de cartographie suivant : la liste des comptes disposant de droits d’accès privilégiés (appelés « comptes privilégiés ») au SIIV. Cette liste précise pour chaque compte le niveau et le périmètre des droits d’accès associés, notamment les comptes sur lesquels portent ces droits (comptes d’utilisateurs, comptes de messagerie, comptes de processus, etc.)
3.1.8-L’OIV élabore et tient à jour l’élément de cartographie suivant : l’inventaire, l’architecture et le positionnement des services de résolution de noms d’hôte, de messagerie, de relais internet et d’accès distant mis en œuvre par le SIIV.
3.2-Les éléments de cartographie sont, le cas échéant, couverts par le secret de la défense nationale
3.3-Sur demande de l’ANSSI, l’opérateur lui communique les éléments de cartographie mis à jour
Règle 4 – Règle relative au maintien en conditions de sécurité
4.1-L’OIV élabore, tient à jour et met en œuvre une procédure de maintien en conditions de sécurité.
4.2-L’opérateur se tient informé des vulnérabilités et des mesures correctrices de sécurité susceptibles de concerner les ressources matérielles et logicielles de ses SIIV
4.3-L’opérateur installe et maintient toutes les ressources matérielles et logicielles de ses SIIV dans des versions supportées et mises à jour du point de vue de la sécurité
4.4-Préalablement à l’installation de toute nouvelle version, l’opérateur s’assure de l’origine de cette version et de son intégrité
4.5-Préalablement à l’installation de toute nouvelle version, l’opérateur analyse l’impact de cette version sur le SIIV concerné d’un point de vue technique et opérationnel
4.6-Dès qu’il a connaissance d’une mesure correctrice de sécurité, l’opérateur en planifie l’installation, et procède à cette installation dans les délais prévus
4.7-En cas de non installation d’une version supportée ou d’une mesure correctrice de sécurité (lorsque des raisons techniques ou opérationnelles le justifient), l’opérateur met en œuvre des mesures techniques ou organisationnelles pour réduire les risques associés. Il décrit ces mesures dans le dossier d’homologation.
Règle 5 – Règle relative à la journalisation
5.1-L’opérateur de services essentiels met en œuvre sur chaque système d’information essentiel (SIE) un système de journalisation qui enregistre les évènements pertinents pour la sécurité
5.2-Les événements enregistrés par le système de journalisation sont horodatés au moyen de sources de temps synchronisées.
5.3-Les événements enregistrés par le système de journalisation sont centralisés
5.4-Les événements enregistrés par le système de journalisation sont archivés pendant une durée d’au moins six mois. Le format d’archivage des événements permet de réaliser des recherches automatisées sur ces événements.
Règle 6 – Règle relative à la corrélation et l’analyse de journaux
6.1-L’opérateur d’importance vitale met en œuvre un système de corrélation et d’analyse de journaux qui exploite les événements enregistrés par le système de journalisation.
6.2-Le système de corrélation et d’analyse de journaux est installé et exploité sur un système d’information mis en place exclusivement à des fins de détection d’événements susceptibles d’affecter la sécurité des systèmes d’information.
6.3-L’opérateur ou le prestataire mandaté à cet effet installe et exploite ce système de corrélation et d’analyse de journaux selon les règles fixées par le référentiel PDIS.
Règle 7 – Règle relative à la détection
7.1-L’OIV met en œuvre un système de détection qualifié de type « sonde d’analyse de fichiers et de protocoles », qui analyse l’ensemble des flux échangés entre les SIIV et les systèmes d’information tiers à ceux de l’opérateur.
7.2-Les systèmes de détection sont exploités selon les règles fixées par le référentiel PDIS. Ils sont exploités par un service de l’Etat ou un prestataire qualifié à cet effet .
Règle 8 – Règle relative au traitement des incidents de sécurité
8.1-L’OIV élabore, tient à jour et met en œuvre une procédure de traitement des incidents
8.2-L’opérateur ou le prestataire mandaté à cet effet procède au traitement des incidents selon les règles fixées par le référentiel PRIS
8.3-Un système d’information spécifique doit être mis en place pour traiter les incidents, notamment pour stocker les relevés techniques relatifs aux analyses des incidents. Ce système est cloisonné vis-à-vis du SIIV concerné par l’incident.
8.4-L’opérateur conserve les relevés techniques relatifs aux analyses des incidents pendant une durée d’au moins six mois.
8.5-Il tient ces relevés techniques à la disposition de l’Agence nationale de la sécurité des systèmes d’information.
8.6-Le cas échéant, ces relevés techniques sont couverts par le secret de la défense nationale.
Règle 9 – Règle relative au traitement des alertes
9.1-L’OIV met en place un service de permanence lui permettant de prendre connaissance, à tout moment et sans délai, d’informations transmises par l’ANSSI relatives à des incidents, des vulnérabilités et des menaces.
9.2-Il met en œuvre une procédure pour traiter les informations ainsi reçues et le cas échéant prendre les mesures de sécurité nécessaires à la protection de ses SIIV.
9.3-L’opérateur communique à l’Agence nationale de la sécurité des systèmes d’information les coordonnées (nom du service, numéro de téléphone et adresse électronique) tenues à jour du service de permanence.
Règle 10 – Règle relative à la gestion de crises
10.1-Procédure de gestion de crises en cas d’attaques informatiques majeures
10.1.1-L’opérateur d’importance vitale élabore, tient à jour et met en œuvre une procédure de gestion de crises en cas d’attaques informatiques majeures, conformément à sa politique de sécurité des systèmes d’information.
10.1.2-Cette procédure décrit les moyens techniques et organisationnels dont dispose l’opérateur pour mettre en œuvre les mesures décidées par le Premier ministre en cas de crises.
10.1.3-La procédure précise les conditions dans lesquelles ces mesures peuvent être appliquées compte tenu des contraintes notamment techniques et organisationnelles de mise en œuvre.
Règle 11 – Règle relative à l’identification
11.1-L’opérateur d’importance vitale crée des comptes individuels pour les utilisateurs accédant aux ressources de ses SIIV.
11.2-L’opérateur d’importance vitale crée des comptes individuels pour les processus automatiques accédant aux ressources de ses SIIV.
11.3-Lorsque des raisons techniques ou opérationnelles ne permettent pas de créer de comptes individuels …
11.3.1-Lorsque des raisons techniques ou opérationnelles ne permettent pas de créer de comptes individuels, l’opérateur met en place des mesures permettant de réduire le risque lié à l’utilisation de comptes partagés et d’assurer la traçabilité de l’utilisation de ces comptes.
11.3.2-Lorsque des raisons techniques ou opérationnelles ne permettent pas de créer de comptes individuels, l’opérateur décrit les mesures de réduction du risque dans le dossier d’homologation du SIIV concerné et les raisons justifiant le recours à des comptes partagés.
11.4-L’opérateur désactive sans délai les comptes qui ne sont plus nécessaires.
Règle 12 – Règle relative à l’authentification
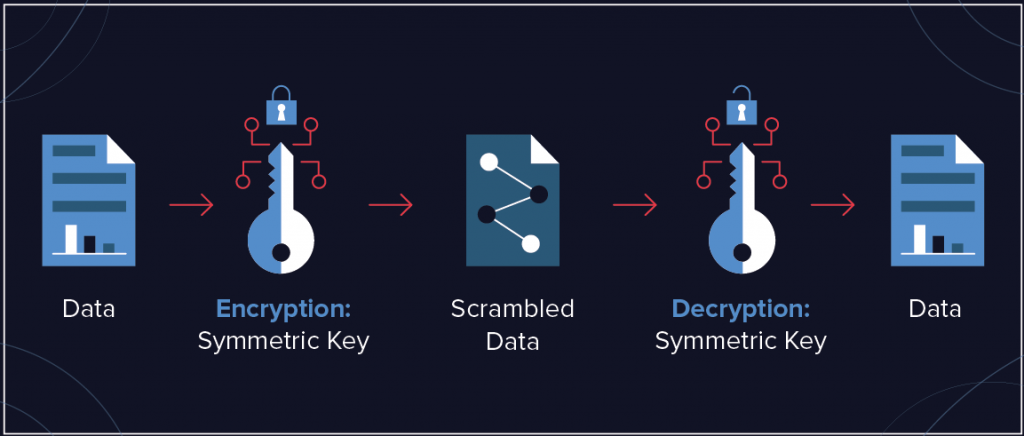
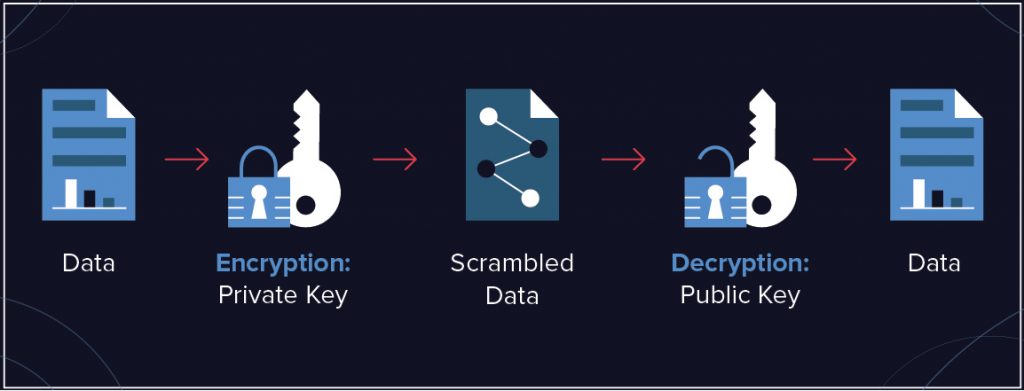
12.1-L’OIV protège les accès aux ressources de ses systèmes d’information d’importance vitale (SIIV), par un utilisateur ou par un processus automatique, au moyen d’un mécanisme d’authentification basé sur un élément secret.
12.2-L’opérateur définit, conformément à sa politique de sécurité des systèmes d’information, les règles de gestion des éléments secrets d’authentification mis en œuvre dans ses SIIV.
12.3-L’opérateur doit modifier les éléments secrets d’authentification lorsqu’ils ont été installés par le fabricant ou le fournisseur de la ressource, avant sa mise en service.
12.4-L’élément secret d’authentification d’un compte partagé doit être renouvelé régulièrement et à chaque retrait d’un utilisateur de ce compte ;
12.5-Les utilisateurs qui n’en ont pas la responsabilité, ne peuvent pas modifier les éléments secrets d’authentification. Ils ne peuvent pas non plus accéder à ces éléments en clair ;
12.6-Lorsque les éléments secrets d’authentification sont des mots de passe, les utilisateurs ne doivent pas les réutiliser entre comptes privilégiés ou entre un compte privilégié et un compte non privilégié ;
12.7-Lorsque les éléments secrets d’authentification sont des mots de passe, ceux-ci sont conformes aux règles de l’art telles que celles préconisées par l’ANSSI, en matière de complexité et en matière de renouvellement.
12.8-Lorsque la ressource ne permet pas techniquement de modifier l’élément secret d’authentification …
12.8.1-Lorsque la ressource ne permet pas techniquement de modifier l’élément secret d’authentification, l’opérateur met en place un contrôle d’accès physique à la ressource concernée
12.8.2-L’opérateur met en place des mesures de traçabilité des accès et de réduction du risque lié à l’utilisation d’un élément secret d’authentification fixe
Règle 13 – Règle relative aux droits d’accès
13.1-L’opérateur définit les accès aux différentes fonctionnalités de chaque ressource
13.2-L’opérateur n’attribue à un utilisateur les droits d’accès à une ressource et à ces fonctionnalités que si cet accès est strictement nécessaire
13.3-L’opérateur n’attribue à un processus automatique les droits d’accès à une ressource et à ses fonctionnalités que si cet accès est strictement nécessaire
13.4-Les droits d’accès sont révisés périodiquement, au moins tous les ans, par l’opérateur
13.5-L’opérateur établit et tient à jour la liste des comptes privilégiés
13.6-Toute modification d’un compte privilégié fait l’objet d’un contrôle formel
Règle 14 – Règle relative aux comptes d’administration
14.1-L’attribution des droits aux administrateurs respecte le principe du moindre privilège
14.2-Les opérations d’administration sont effectuées exclusivement à partir de comptes d’administration
14.3-Les comptes d’administration sont utilisés exclusivement pour les opérations d’administration
14.4-Lorsque l’administration d’une ressource ne peut pas techniquement être effectuée à partir d’un compte spécifique d’administration …
14.3.1-Lorsque l’administration d’une ressource ne peut pas techniquement être effectuée à partir d’un compte spécifique d’administration, l’opérateur met en place des mesures permettant d’assurer la traçabilité et le contrôle des opérations d’administration réalisées sur cette ressource
14.3.2-Lorsque l’administration d’une ressource ne peut pas techniquement être effectuée à partir d’un compte spécifique d’administration, l’opérateur met en place des mesures des mesures de réduction du risque lié à l’utilisation d’un compte non spécifique à l’administration
14.5-L’opérateur établit et tient à jour la liste des comptes d’administration de ses SIE et les gère en tant que comptes privilégiés
Règle 15 – Règle relative aux systèmes d’information d’administration
15.1-Les ressources matérielles et logicielles des systèmes d’information d’administration sont gérées et configurées par l’opérateur ou, le cas échéant, par le prestataire qu’il a mandaté pour réaliser les opérations d’administration
15.2-Les ressources matérielles et logicielles des systèmes d’information d’administration sont utilisées exclusivement pour réaliser des opérations d’administration.
15.3-Un utilisateur ne doit pas se connecter à un système d’information d’administration au moyen d’un environnement logiciel utilisé pour d’autres fonctions que des opérations d’administration
15.4-Les flux de données associés à des opérations autres que des opérations d’administration doivent, lorsqu’ils transitent sur les systèmes d’information d’administration, être cloisonnés au moyen de mécanismes de chiffrement et d’authentification conformes aux règles préconisées par l’ANSSI.
15.5-Les systèmes d’information d’administration sont connectés aux ressources à administrer au travers d’une liaison réseau physique utilisée exclusivement pour les opérations d’administration.
15.6-Ces ressources sont administrées au travers de leur interface d’administration physique.
15.7-Lorsqu’ils ne circulent pas dans le système d’information d’administration, les flux d’administration sont protégés par des mécanismes de chiffrement et d’authentification conformes aux règles préconisées par l’ANSSI
15.8-Les journaux enregistrant les événements générés par les ressources utilisées par les administrateurs ne contiennent aucun mot de passe en clair ou sous forme de condensat.
Règle 16 – Règle relative au cloisonnement
16.1-Chaque SIIV est cloisonné physiquement ou logiquement vis-à-vis des autres systèmes de l’opérateur ou des systèmes tiers. Seules les interconnexions strictement nécessaires au bon fonctionnement et à la sécurité sont mises en place
16.2-Chaque SIIV est cloisonné physiquement ou logiquement vis-à-vis des systèmes tiers. Seules les interconnexions strictement nécessaires au bon fonctionnement et à la sécurité sont mises en place
16.3-Lorsqu’un SIIV est lui-même constitué de sous-systèmes, ceux-ci sont cloisonnés entre eux physiquement ou logiquement. Seules les interconnexions strictement nécessaires au bon fonctionnement et à la sécurité sont mises en place
16.4-L’opérateur décrit dans le dossier d’homologation de chaque SIIV les mécanismes de cloisonnement qu’il met en place.
Règle 17 – Règle relative au filtrage
17.1-L’opérateur définit les règles de filtrage des flux de données
17.2-Les flux entrants et sortants des SIIV ainsi que les flux entre sous-systèmes des SIIV sont filtrés au niveau de leurs interconnexions
17.3-L’opérateur établit et tient à jour une liste des règles de filtrage mentionnant l’ensemble des règles en vigueur ou supprimées depuis moins d’un an
17.4-L’opérateur décrit dans le dossier d’homologation de chaque SIIV les mécanismes de filtrage qu’il met en place.
Règle 18 – Règle relative aux accès à distance
18.1-L’accès de l’opérateur ou d’un prestataire au SIIV, à travers un réseau tiers, est protégé par des mécanismes de chiffrement et d’authentification conformes aux règles préconisées par l’ANSSI.
18.2-Les équipements utilisés pour accéder au SIIV, à travers un réseau tiers, sont gérés et configurés par l’opérateur ou, le cas échéant, par le prestataire mandaté.
18.3-Les mémoires de masse des équipements utilisés pour accéder au SIIV, à travers un réseau tiers, sont en permanence protégées par des mécanismes de chiffrement et d’authentification conformes aux règles préconisées par l’ANSSI
Règle 19 – Règle relative à l’installation de services et d’équipements
19.1-L’opérateur installe sur ses SIIV les seuls services et fonctionnalités qui sont indispensables au fonctionnement ou à la sécurité de ses SIIV. L’opérateur désactive les services et les fonctionnalités qui ne sont pas indispensables
19.2-L’opérateur ne connecte à ses SIIV que des équipements, matériels périphériques et supports amovibles qu’il a dûment répertoriés et qui sont indispensables au fonctionnement ou à la sécurité de ses SIIV
19.3-Les supports amovibles inscriptibles connectés aux SIIV sont utilisés exclusivement pour les besoins de ces SIIV
19.4-L’opérateur procède, avant chaque utilisation de supports amovibles, à l’analyse de leur contenu, notamment à la recherche de code malveillant.
19.5-L’opérateur met en place, sur les équipements auxquels sont connectés ces supports amovibles, des mécanismes de protection contre les risques d’exécution de code malveillant provenant de ces supports
Règle 20 – Règle relative aux indicateurs
20.1-L’OIV évalue pour chaque SIIV, les indicateurs suivants .
20.1.1-L’OIV évalue, pour chaque SIIV, des indicateurs relatifs au maintien en conditions de sécurité des ressources
20.1.1.1-Pourcentage de postes utilisateurs dont les ressources systèmes ne sont pas installées dans une version supportée par le fournisseur ou le fabricant
20.1.1.2-Pourcentage de serveurs dont les ressources systèmes ne sont pas installées dans une version supportée par le fournisseur ou le fabricant
20.1.1.3-Pourcentage de postes utilisateurs dont les ressources systèmes ne sont pas mises à jour ou corrigées du point de vue de la sécurité depuis au moins quinze jours à compter de la disponibilité des versions mises à jour
20.1.1.4-Pourcentage de serveurs dont les ressources systèmes ne sont pas mises à jour ou corrigées du point de vue de la sécurité depuis au moins quinze jours à compter de la disponibilité des versions mises à jour.
20.1.2-L’OIV évalue, pour chaque SIIV, des indicateurs relatifs aux droits d’accès et à l’authentification des accès aux ressources
20.1.2.1-Pourcentage d’utilisateurs accédant au SIIV au moyen de comptes partagés
20.1.2.2-Pourcentage d’utilisateurs accédant au SIIV au moyen de comptes privilégié
20.1.2.3-Pourcentage de ressources dont les éléments secrets d’authentification ne peuvent pas être modifiés par l’opérateur
20.1.3-L’OIV évalue, pour chaque SIIV, des indicateurs relatifs à l’administration des ressources
20.1.3.1-Pourcentage de ressources administrées dont l’administration est effectuée à partir d’un compte non spécifique d’administration
20.1.3.2-Pourcentage de ressources administrées dont l’administration ne peut pas être effectuée au travers d’une liaison réseau physique ou d’une interface d’administration physique
20.1.3.3-Pourcentage de ressources administrées dont les flux d’administration ne peuvent pas être protégés par des mécanismes de chiffrement et d’authentification lorsque ces flux ne circulent pas dans le système d’information d’administration.
20.2-L’opérateur précise pour chaque indicateur la méthode d’évaluation employée et, le cas échéant, la marge d’incertitude de son évaluation
20.3-Les indicateurs ainsi réunis sont des documents confidentiels susceptibles de contenir des informations dont la révélation est réprimée par les dispositions de l’article 226-13 du code pénal. Ils sont, le cas échéant, couverts par le secret de la défense nationale.
20.4-L’opérateur communique, une fois par an, à l’Agence nationale de la sécurité des systèmes d’information, ces indicateurs mis à jour, selon le moyen approprié à la sensibilité des informations déclarées.